
Les récents classements de Chatbot Arena, récompensant d’anciens LLMs (pour Large Language Models ou « Grand Modèles de Langage » en français), ne révèlent pas le pot-aux-roses. Voilà ce qui manque.
Commençons par le contexte.
Chatbot Arena est une application web qui permet d’évaluer les LLM en collectant les votes des utilisateurs en aveugle. À chaque tour, on propose deux générations issues de modèles de langage différents à un utilisateur. L’utilisateur choisit alors celle qu’il juge la meilleure sans savoir quel modèle a généré quelle réponse.
Les responsables d’Arena utilisent ensuite les quelques 130 000 votes recueillis pour calculer les notes Elo. Le système de classement Elo a été développé à l’origine pour évaluer les performances des joueurs d’échecs en déterminant leurs compétences de jeu (modèles linguistiques). Les points gagnés ou perdus par les joueurs sont calculés en fonction de leurs victoires ou de leurs défaites. Si un joueur bat un joueur mieux classé, il gagne plus de points. S’il perd contre un joueur moins bien classé, il perd plus de points.
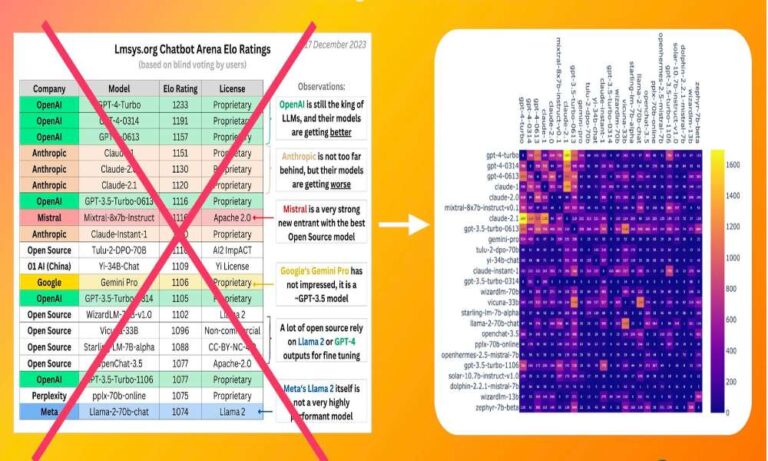
Les captures d’écran des classements qui circulent actuellement sur LinkedIn et X sont trompeuses. Elles indiquent, par exemple, que Claude 1 serait plus performant que Claude 2.1. Mais comment cela se fait-il ?
Supposons que le meilleur joueur d’échecs du monde entame sa carrière professionnelle. Bien qu’il gagne tous ses matchs, il lui faut du temps pour accumuler suffisamment de points pour être reconnu à juste titre comme le meilleur joueur.
Les modèles linguistiques de Chatbot Arena subissent un sort similaire. Claude 2.1 n’a pas encore disputé suffisamment de « matchs » pour gagner et arriver en tête du classement.
Pour combler cette lacune, il serait bon d’ajouter une colonne supplémentaire qui prendrait en compte le rapport des victoires par rapport aux modèles de même rang, et pas seulement la quantité de victoires. Jusque-là, vous pouvez faire défiler le classement un peu plus bas pour trouver le ratio de victoire de chaque modèle avant de couronner un modèle à la pointe de la technologie.
Rejoignez des milliers de chercheurs et d’ingénieurs de réputation mondiale de Google. Stanford, OpenAI et Meta pour rester à la pointe de l’IA http://aitidbits.ai